近日,百图生科与清华大学联合提出了一种名为 xTrimo Protein General Language Model (xTrimoPGLM) 的模型,参数量高达千亿(100B)。相关成果于 2023 年 7 月 7 日在 biorxiv 上发布。

论文链接:https://www.biorxiv.org/content/10.1101/2023.07.05.547496v3
自然语言处理(NLP)领域中的预训练模型相关进展已经被成功地用于学习蛋白质序列中隐藏的生物信息。现在大多数的蛋白质预训练模型都受限于自动编码或自回归预训练目标,这使得它们难以同时处理蛋白质理解(例如,蛋白质结构预测)和生成任务(例如,药物设计)。
这篇论文提出统一的蛋白质语言模型,xTrimoPGLM,通过一个创新的预训练框架来同时处理这两种类型的任务。xTrimoPGLM 主要技术贡献是探索了这两种类型目标之间的兼容性以及共同优化的可能性,并基于此训练了一个前所未有的 1000 亿参数规模的蛋白质语言模型,并消耗了 1 万亿 Tokens,模型 FLOPs 达到 6.2e+23,达到和 175B 参数的 GPT-3 一个量级。
在理解任务上,xTrimoPGLM 在多种蛋白质理解任务(15 项任务中的 13 项任务)中显著优于其他先进基线。在生成任务上,xTrimoPGLM 能够生成与自然蛋白质结构类似的新蛋白质序列。
此外,文章基于相同的框架额外训练了一个 12 亿参数的抗体模型(xTrimoPGLM-Ab),其在预测抗体自然性和结构方面取得了市面上最好的效果,并且显示出比 AlphaFold2 更快的推理速度(数十倍到数千倍)。综合来看,这些结果充分展示了 xTrimoPGLM 在理解和生成蛋白质序列方面的强大能力和广阔的应用前景。
不同类型的蛋白质相关任务需要蛋白质语言模型(Protein Language Model,PLM)提供各异的输出。具体的,蛋白质理解任务,如二级结构预测等,需要 PLM 提供精确的氨基酸和序列级别的表示;而蛋白质设计任务,如抗体或酶的设计,依赖于 PLM 的生成能力。然而,当前的 PLM 因为其单一的预训练框架的限制,大多只能处理一种类型的任务。
事实上,蛋白质的理解和生成都反映了蛋白质数据的分布信息,Meta 之前使用 ESM(基于 Masked Language Model 的蛋白质大模型)做生成的工作也证实了这一点,指出蛋白质理解预训练模型可以通过一些采样策略进行蛋白质设计。这进一步支撑了这两种看似不同的任务的统一性,如果能够使用同一个训练框架去处理这两种任务,将会进一步增强模型对蛋白质数据的拟合能力。
虽然 NLP 领域生成式模型(例如 UL2R, GPT) 已经成为主流范式,通过把数据标签映射到整个文本空间,结合指令微调来生成各式各样的任务的答案,但 PLM 还无法实现这一点。实际上,蛋白质的应用仍然依赖于将表示与下游任务特定标签(如结构预测的 3D 坐标)之间的桥接,这在很大程度上依赖于 BERT 样式的训练来处理蛋白质理解任务。因此,需要同时进行这两种训练目标。
本文介绍的 xTrimo 蛋白质通用语言模型(xTrimoPGLM)预训练框架,巧妙地统一了两种类型的预训练任务,使模型能同时处理多种与蛋白质相关的任务。研究团队通过全面的实验评估了 xTrimoPGLM 框架的有效性。在蛋白质理解任务的情况下,xTrimoPGLM-100B 在多种评估中表现出色,涵盖了蛋白质结构、功能、交互和可开发性等领域的 15 项任务。
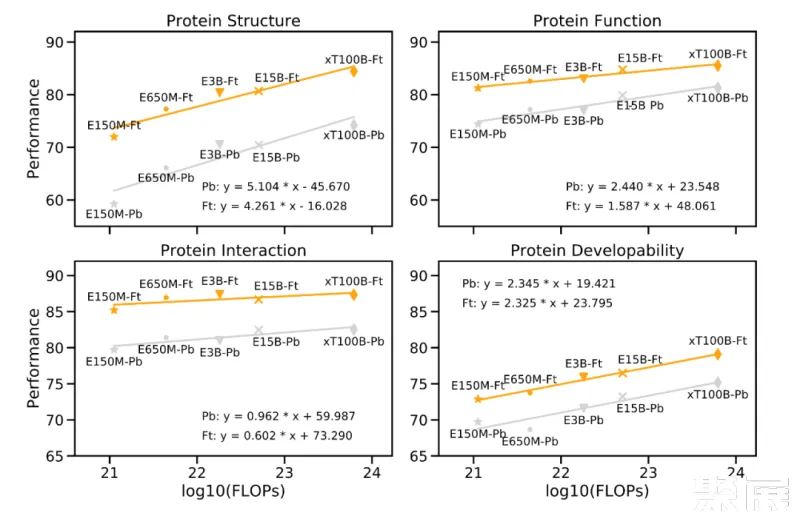
"Scaling Law" 是衡量大型语言模型的重要原则,模型的性能应随着模型参数大小、数据量、计算量按比例指数增加而线性增长。实际上,研究团队在下游任务上的实验结果验证了这一定律,证明了大型模型在处理复杂任务时的必要性。
如下图所示,性能改善与预训练计算量增加之间的关系。以 Meta 的 ESM-2 为参考,随着蛋白质语言模型(PLM)的计算量呈指数增长,蛋白质的下游性能仍然会线性增长(每个大类有 3-4 个任务,数值表示这些任务的平均值)。
在蛋白质生成任务中,xTrimoPGLM-100B 展示了生成不同长度和序列的新蛋白质序列的能力,这是通过调整生成超参数实现的。值得注意的是,当与自然蛋白质进行比较时,xTrimoPGLM-100B 展示了生成结构相似但序列相异的新蛋白质序列的能力。这再次验证了大型模型对于复杂任务的重要性,进一步证实了遵循 "Scaling Law" 进行模型设计的决定是正确的。
同时,研究团队还开发了一种当前更具实用意义的具有 12 亿参数的抗体 PLM,即 xTrimoPGLM-Ab-1B。这种模型在 OAS 抗体数据库上进行 fine-tuning,处理了超过 1 万亿个 token。它在抗体的自然性和结构预测任务上达到了目前最优秀的性能。由于不依赖于外部库的检索和多序列对齐(Multiple Sequence Alignment),所以结构预测在速度上比 Alphafold2 模型提升成百上千倍,这对于基于抗体药物发现 AI 制药公司至关重要。
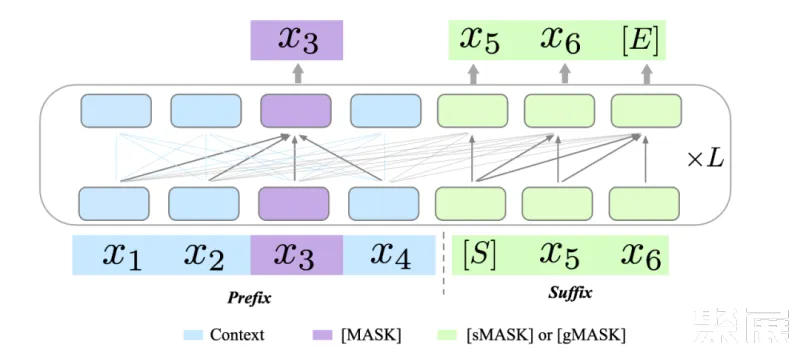
原始的 GLM 模型利用两种不同的预训练目标来提升其生成能力:1)跨度生成(Span Generation,简称 sMask),用于恢复句子中的短空白;2)长文本生成(Long-text Generation,简称 gMASK),用于在提供前缀上下文的基础上生成随机长度的序列。为了进一步提升 xTrimoPGLM 的理解能力,团队在 prefix 区域引入了被用作理解目标的 Masked Language Model(MLM,即 [MASK])。这样的设计确保了 xTrimoPGLM 能生成精确的残基级和序列级表示。
当使用 [MASK] 标识符时,xTrimoPGLM 的功能类似于 BERT。相反,当使用 [sMASK] 或 [gMASK] 时,xTrimoPGLM 的行为类似于 PrefixLM 或 GPT。总的来说,xTrimoPGLM-100B 的预训练阶段可以分为两个阶段。首先,利用 MLM 进行预训练以增强其表示能力,主要目标是快速减少损失水平。第二阶段,使用结合 MLM 和 GLM 损失的统一目标进行训练,以提升理解和生成能力。
NLP 领域大量探索了统一的预训练模式,但大多还是采样了同样的训练模式(自回归或自编码)。为了满足统一的蛋白质预训练模型的需求,需要将 BERT 样式的目标引入到预训练语言模型中,以增强模型的表示能力,同时也需要引入 GPT 样式的目标,以确保模型的生成能力。在最开始研究团队使用 Probing 策略探索 Contact Map Prediction 的任务时,发现仅仅依靠基于下一个词预测的生成式语言模型,效果会有大幅度的下降。
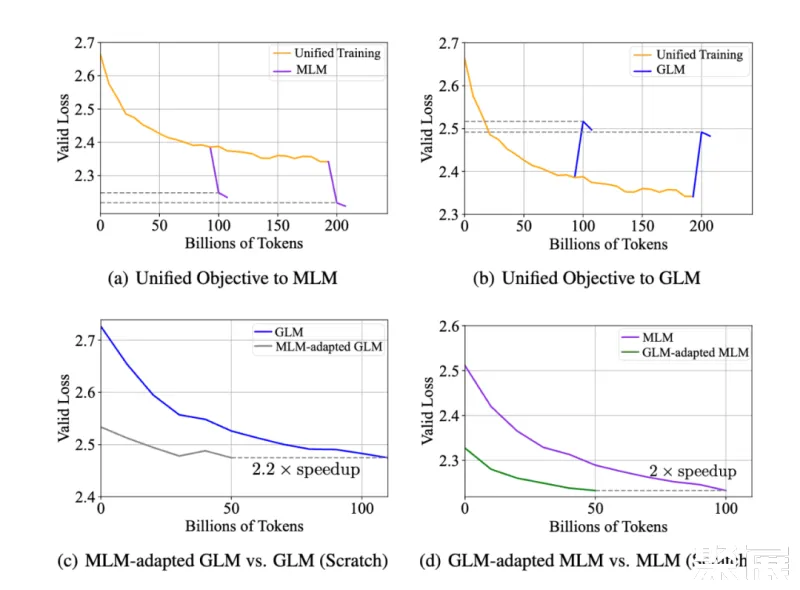
兼容性实验:在实证分析中,研究团队在 xTrimoPGLM-150m 模型上探究了同时优化两个不同目标的可行性。结果如下图 (a)(b) 所示,即使两种预训练目标看似冲突,MLM 损失和 GLM 损失也可以同时优化,反之亦然,即统一的训练可以很快的适配到 MLM 或者 GLM 上,并不会影响两者的收敛情况。
研究团队还探究了 MLM 与 GLM 两种目标是否能相互加速收敛,结果如图 (c)(d)。
-
MLM-adapted GLM:接着 MLM 预训练后的模型,继续训练 GLM 目标函数;
-
GLM-adapted MLM:接着 GLM 预训练后的模型,继续训练 MLM 目标函数;
总的说来,基于预训练后的模型中继续训练的模型,与从头开始训练的模型相比,其收敛速度明显加快。这些实验观察到:在蛋白质数据分布并不依赖于特定的训练模式,从而缩小了自编码 PLMs(如 ESM)和自回归 PLMs(如 ProGen2)之间的差距,为 100B 训练流程提供了支持。
训练稳定性是成功训练 100B 规模大型语言模型的决定性因素。xTrimoPGLM 从 GLM-130B 的实现中借鉴了一些想法并解决了许多不稳定训练的问题。然而,xTrimoPGLM-100B 在从训练的第一阶段过渡到第二阶段时仍然会遇到灾难性的训练崩溃(小规模的模型(10B 规模)中并未观察到),即使一开始只将 1% 的 GLM 损失加入预训练也可能触发这些崩溃。
下图可以看到,如果直接给 GLM 分配一个比例 ,在训练初期,grad norm 都会出现 spike(橙,蓝,绿线)。

为了缓解这个问题,研究团队提出了一种平滑过渡策略。主要分为两个阶段。在第一阶段,主要目标是逐步提高 GLM 损失的比例,达到预期的数量。具体来说,给定一个期望的 GLM 损失比例 R,按照线性增长,以 K 步从 0 增加到 R。在这个阶段应该将学习率保持在极低的水平。完成过渡后,学习率可以按照预定义的脚本在几百个 steps 内逐渐回升至原来的水平 (紫线)。实际上,最后的 xTrimoPGLM-100B 训练运行只在过渡阶段经历了损失分歧情况,但是由于硬件故障多次失败,导致经常性的更换节点和重启。
为了能够尽可能的映射整个蛋白世界, xTrimoPGLM-100B 的预训练模型的训练数据集整合自两个广泛的数据源:Uniref90 和 ColAbFoldDB。
结合这两个数据源,预训练模型数据集充分利用了这两个数据源的优势,既有广泛的生物分类覆盖,又有多样的环境生态位蛋白质序列,全面而详尽地映射了生物世界中的蛋白质资源。

xTrimoPGLM-100B 模型的训练过程复杂且耗费资源,团队耗费了 160 天的时间,开发团队使用了 96 台 DGX-A100 GPU 服务器(每台服务器拥有 8×40G 的 GPU)以混合精度(FP16)进行训练,消耗了 1 万亿的 tokens,由于大多数现有的大型语言模型在训练上存在严重不足,所以开发团队现在仍然在继续训练 xTrimoPGLM-100B 模型,以处理尽可能多的 tokens。
模型采用了 3D 并行策略,基于 DeepSpeed 进行了 4 路张量并行、8 路流水线并行,并且采用了 Zero Stage 1 进行训练。模型具有 72 个 Transformer 层,80 个 head,以及 10,240 维和 31,744 个 FNN 的维度。使用了 DeepNorm 初始化 Post-LN,并且采用了 Embedding Layer Gradient Shrink (EGS) 稳定训练,以及使用了 2D ROPE 位置编码技术。为了提升训练效率,每个样本由多个蛋白拼接再一起,使用 < eos > 区分开来,包含固定的 2,048 的序列长度。最终单卡的 TFLOPs 在 120-135 之间,68 examples/sec, 如果是 80G 的 A100,经过减少重算可到 92 examples/sec。下表展示了大部分超参数的配置。

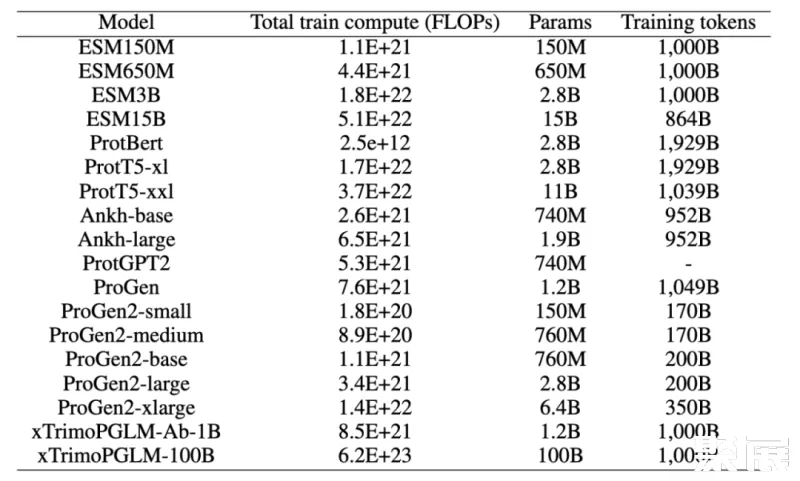
团队也对比了当前比较热门的预训练模型的 FLOPs,目前生物领域不同模型的结构也存在比较大的区别, 所以在 FLOPs 的计算上,团队考虑尽可能详细统计,包括 query、 key、value 的转换,Attention Matrix 的计算,注意力之后线性变换,MLP 中的变换,以及最后到 vocab 维度的映射,以及语言模型头(如果存在的话)中的线性转换等,可以看到,xTrimoPGLM-100B 高出其他模型一到两个量级。
为了全面评估 xTrimoPGLM-100B 模型,研究团队对 4 个领域内,15 个下游的蛋白质相关任务进行了基准测试。测试结果表明,xTrimoPGLM-100B 在蛋白质结构、蛋白质可开发能力、蛋白质相互作用和蛋白质功能等四个主要类别的任务中,都表现出了显著的优势。在这些任务中,xTrimoPGLM-100B 模型与微调技术的组合取得了优异的成绩,大部分超越了当前最先进的方法,从而推动这个领域的进步。
需要强调的是,下表对比主要从任务的角度进行,而不是一个完全公平的对比,因为 xTrimoPGLM-100B 在取得这些结果时,采用了这个领域大模型之前都不太微调技术。这些结果的大部分来自对论文直接引用,并使用相同的数据划分策略,有一些没有 benchmark 的任务,研究团队使用了 ESM-15B + finetuning 的策略作为 benchmark, 实际上,在所有任务中,研究团队也使用过这种策略,发现 ESM2-15B/3B + finetuning 在不少任务可以直接达到 SOTA,但是,目前大部分的蛋白质大语言模型很少微调技术,更多的是把 PLMs 作为特征提取器使用。
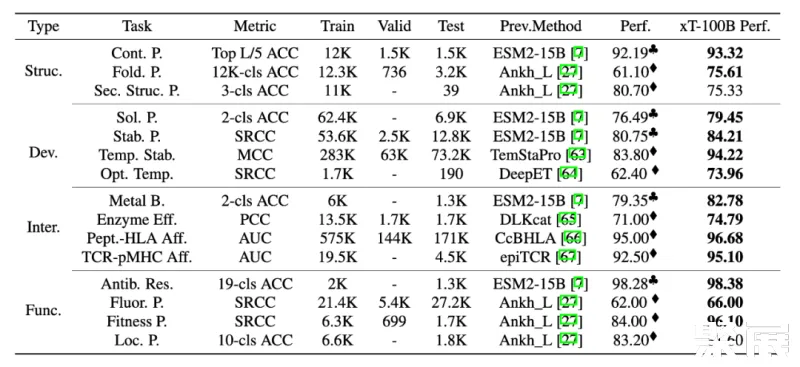
另一方面,为了表明 xTrimoPGLM 大模型的有效性,研究团队也给出来和 ESM2-15B 以及 150M 的在相同训练设置下的对比实验,使用相对较小的 ESM2-150M 模型作为指标,主要来理解各种下游蛋白质相关任务的难度程度。这些任务包括基于 feature-based 的 Probing 和 联合大模型参数的 Finetuning,xTrimoPGLM-100B 在大多数蛋白质相关任务中仍然展现出了优势。
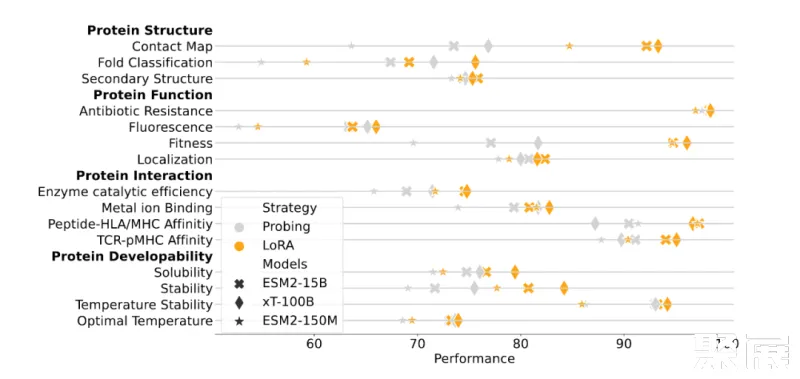
总的来说,xTrimoPGLM-100B 在 15 项任务中的 12 项上表现得比 ESM2-15B 更好。研究结果也揭示了一个规律:尽管其它的方法(比如 Ankh)在试图寻找一种途径,即在不依赖大规模语言模型的情况下,构建高效、低成本、有知识指导的蛋白质语言模型,但在模型的性能还是与模型规模密切相关,这表明,扩大模型规模可能是一个简单而有效的方法,能够在通用的蛋白质相关任务中提升模型的表现。这为未来对蛋白质预训练模型进一步的研究提供了指导。
为了进一步确定 xTrimoPGLM 框架的通用性,团队把该框架应用在抗体蛋白预训练上。考虑到训练资源的限制和抗体数据的多样性不足(大部分长度相似且有相似的框架区域),团队没有直接在 xTrimoPGLM-100B 上进行精调,而是构建了一个 12 亿参数模型 xTrimoPGLM-Ab-1B,在包含 10 亿抗体序列的 OAS 数据集对模型进行训练。
考虑到 CDRs 是抗体最重要的部分,团队对 40% 的样本进行完整的 CDRs 掩码处理,另外 40% 的样本随机掩码处理,而剩下的 20% 则使用 MLM 目标。由于 [gMASK] 在抗体任务中的需求较少,所以没采用该 loss。xTrimoPGLM-Ab-1B 先在通用蛋白序列上训练 500B 的 token,随后在 OAS 的数据上接着训练 500B 的 token。一共使用 128 块 Nvidia A100 80G GPU 卡进行混合精度训练,大约需要 168 小时。
对于 antibody-based 的药物设计,有两项必不可少的任务就是序列自然度 (Naturalness) 以及抗体结构预测 (Antibody Structure Prediction), 下面分别介绍。
研究团队使用了百图生科湿实验室获得的蛋白质表达实验数据集来评估各种模型的性能。具体来说,任何产生的纯化蛋白质少于 10 mg/L 的样本都被归类为未表达,而产生超过 10 mg/L 的样本被认为是成功合成的。第一个数据集(数据集 1)包括 601 个抗体序列,来自在 CHO 和 HEK293 细胞上进行的湿实验。其中,成功表达的有 516 个。第二个数据集(数据集 2)包含了 98 个针对特定抗原的人类抗体序列,其中 90 个成功表达。评估采用 zero-shot 方式评估,不针对标签微调,仅通过计算序列困惑度(PPL)和伪困惑度(PPPL)给序列打分。
结果显示,在这两个数据集中,xTrimoPGLM-Ab-1B 均优于其他基准模型。而且,进一步对 xTrimoPGLM-Ab-1B 进行精调,分别得到了 xTrimoPGLM-Ab-1B-GLM 和 xTrimoPGLM-Ab-1B-MLM 两个模型。结果显示,这两个模型在数据集 2 上的 AUC 得分均有 0.02 的提升。
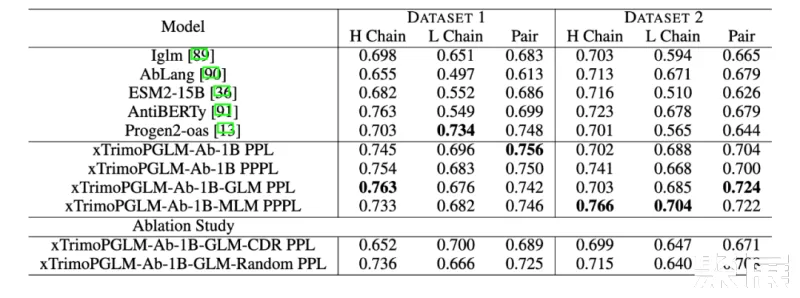
作者们还进行了消融研究,以证明随机区域掩码和 CDR 区域掩码的重要性。实验证明,同时使用这两种目标在数据集 1 和数据集 2 上的表现均优于仅使用其中一种任务的模型,这突显了组合使用这两类目标的重要性。
这个任务目标是根据抗体的序列来预测其结构,实验涵盖了单链结构预测和复杂结构预测,即 VH-VL 复合物。
单链结构预测的数据集源自 2022 年 4 月 13 日之前的 RCSB Protein Data Bank (PDB)。该数据集包含 19k 个抗体链(VL 或 VH)。通过过滤,最终获得了约 7.5k 个独特的序列。另一个数据集,VH-VL 复合物,包含了大约 4.7k 个来自 PDB 的抗体。评估标准为根均方偏差(RMSD)和 TM-score。复杂结构预测还包括 DockQ 评估。
相比当前流行的结构预测模型(如 ESMFold, AlphaFold2),xTrimoPGLM-AbFold 做了以下改变:1) 去除了 MSA 和模板搜索模块;2) 将下游 evoformer 模块的数量从 48 减少到 1。
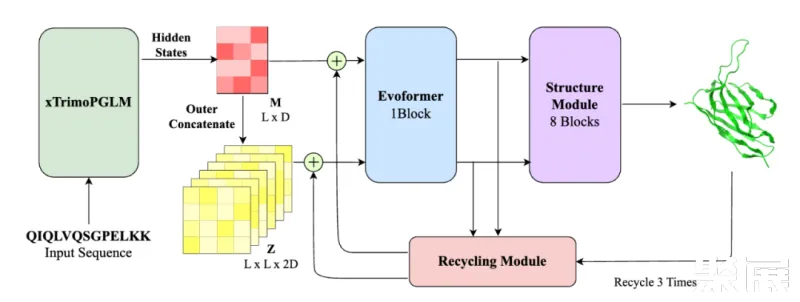
对于单链结构预测任务,研究团队对比了 Alphafold2 以及四个基于 PLM 的模型:OmegaFold、ESMFold、IgFold 和 xTrimoAbFold。
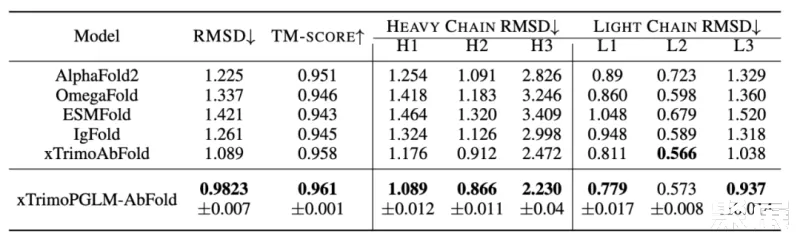
结果如表所示,xTrimoPGLM-AbFold 在所有抗体结构预测相关的指标上都显著优于其他模型,进一步说明,在预训练模型对数据分布拟合的足够好时,只需微调一个额外的 Evoformer 模块以及不依赖 MSA 和模板的情况下,就能成为领先的抗体结构预测模型。
对于 VH-VL 复杂结构的预测,研究团队比较了 ZDock、ClusPro、EquiDock、HDOCK 以及 AlphaFold-Multimer。
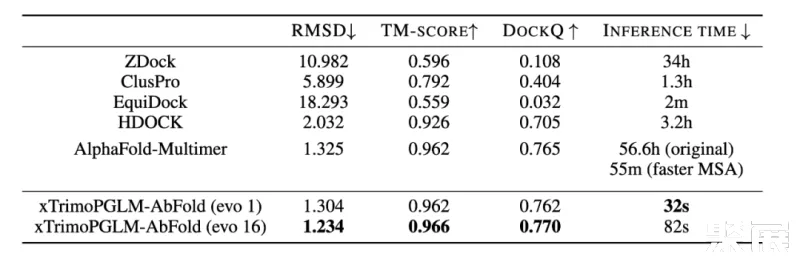
上表也展示了不同模型在 VH-VL 复合物性能上的表现。AlphaFold-Multimer 使用了 MSA 和模板信息,效果优于大多数结构预测算法。而 xTrimoPGLM-AbFold 不使用任何 MSA 或模板信息,与 AlphaFold-Multimer 的表现相当,这说明 xTrimoPGLM-Ab-1B 已经学习了足够丰富的抗体信息。更重要的是,其推理速度比 AlphaFold-Multimer 快了 6300 倍,而且比使用了 MSA 加速搜索策略的 AlphaFold-Multimer 快了 103 倍。在 AI 制药引擎中,往往需要对生成的候选序列快速进行结构预测,以便算出 reward,进行下一轮的迭代,速度的提升决定了引擎的效率。
此外,团队将 Evoformer 模块的数量增加到 16 个时,xTrimoPGLM-AbFold 在所有指标上都达到了最佳性能,同时速度还比原来的 AlphaFold-Multimer 快 2400 倍,比加速 MSA 搜索版的 AlphaFold-Multimer 快 40 倍。值得注意的是,当 Evoformer 模块的数量从 1 增加到 16 时,效果只有少量的提升,这表明预训练模型已经学习到了足够的序列信息,可以精确地预测原子位置。
在探索 xTrimoPGLM 生成自然功能序列的能力上,研究团队生成了数千个序列并预测其对应的三维折叠结构。研究团队发现该模型能够生成重要的二级结构,包括 alpha 螺旋和 beta 折叠,这些都是更复杂三级结构的基础。此外,模型生成的序列与自然序列相似性低,这为之后的药物合成提供了更多的选择。
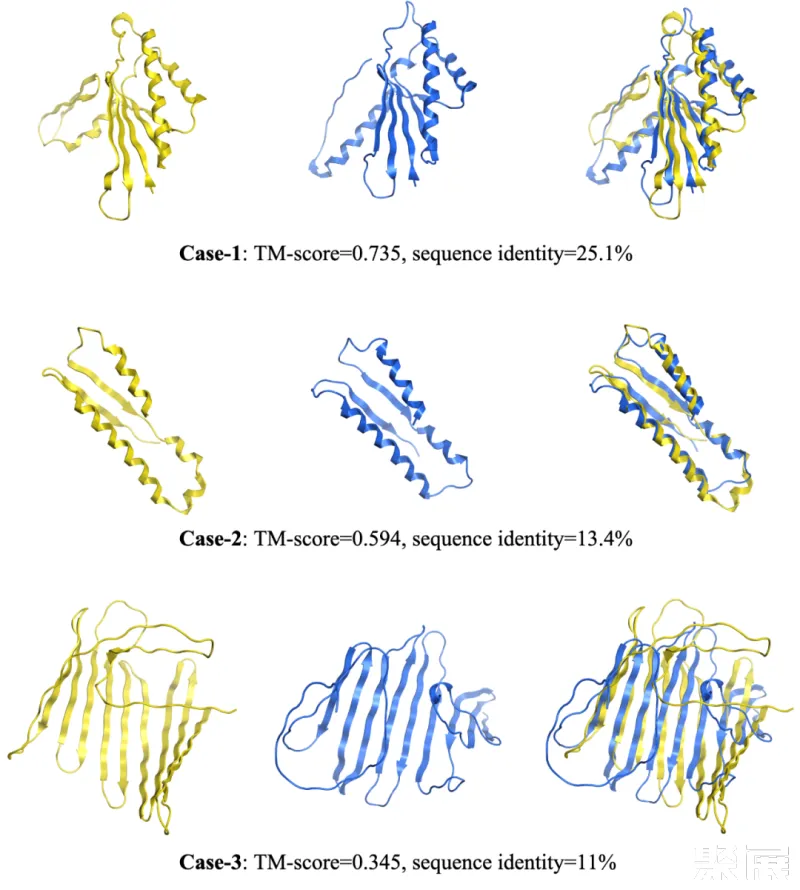
但是,如何生成高质量序列还有着巨大的挑战。首先,当处理超过 200 个氨基酸的序列时,模型往往生成大量的循环,而不是自然蛋白质般的结构。其次,模型在生成过程中经常会产生重复的问题,这可能源于模型倾向于选择在局部最大化输出概率的选项。对此团队尝试使用了 n-gram penalty 来减少生成重复序列的可能性,但研究团队发现许多示例都展示出低复杂度的序列(例如,局部重复),预测的结构中包含长循环无序区域,推测是 n-gram 惩罚可能阻碍了模型生成正确序列的能力(下图第一行)。在去除 n-gram penalty 后,模型能够生成正常的结构(下图第二行)。

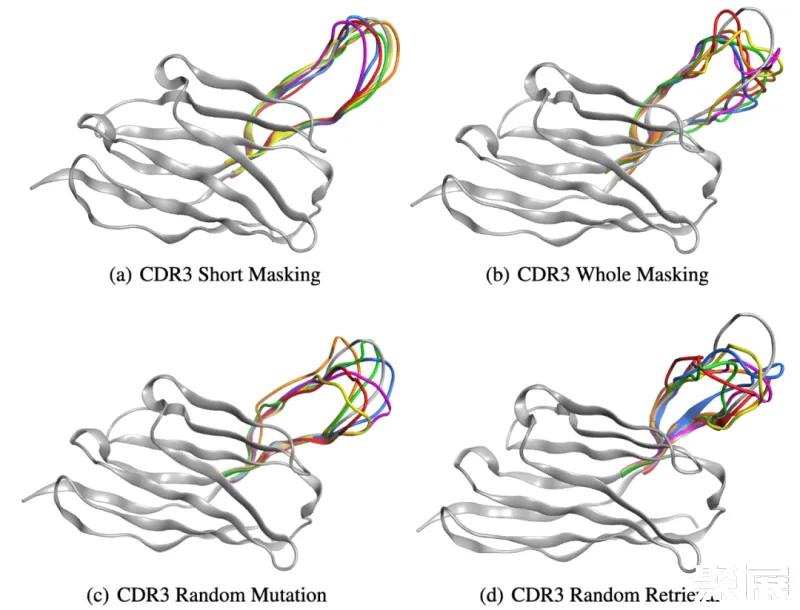
团队近一步展示了 xTrimoPGLM-Ab-1B 模型的生成能力,选择了一个能与 SARS-CoV-2-WT 链接的重链抗体序列,并采用四种不同的策略重新设计了该序列的 CDR3 区域。因为 CDR3 区域在抗体或 T 细胞受体的结构中起着关键作用,并且具有显著的变异性,对抗原识别的特异性起着重要的作用。以下是定义的四种策略:
-
CDR3 短序列掩码(CSM):对 CDR3 部分区域进行掩码重设计。
-
CDR3 全序列掩码(CWM):对 CDR3 全部区域进行掩码重设计。
-
CDR3 随机突变(CRM):对 CDR3 区域内特定位点的随机 3-6 个位置进行突变。
-
CDR3 随机检索(CRR):使用来自 SARS-CoV-2 野生型库中其他抗体的序列随机替换 CDR3 区域。
团队通过 xTrimoPGLM-Ab-1B 生成了一组 6,000 个抗体。研究团队随机选择了六种抗体,并使用 xTrimoPGLM-AbFold 作为结构预测模型。CSM 和 CWM 策略能够生成不同长度的序列,而不必进行突变或删除。相比之下,由两个并行基线 CRM 和 CRR 生成的序列显示出相当大的无序性,无论是否存在少量突变或完全替换整个 CDR3 片段。研究团队的分析进一步发现,编辑距离与生成抗体 CDR3 区域的结构之间存在关系。特别是,随着编辑距离的增加,CDR3 区域的结构倾向于退化,即使是大的生成模型目前也仍然面临限制。
通过借鉴 NLP/CV 领域的想法,生物领域的预训练模型近两年雨后春笋般地冒出来,随着模型计算力的提升和生物数据增长,我们期待更多未知的、惊人的发现出现在这个领域中。
尽管仍然存在不少需要继续探索的地方,千亿模型的诞生不仅标志着最前沿的 AI 技术和生物学技术的融合,还意味着一个充满无限可能的未来已经开启。我们期待,这一重量级的模型引领制药领域步入一个新的黄金时代,为人类健康和科学事业开创更加光明的未来。
© THE END
转载请联系本获得授权
投稿或寻求报道:content@jiqizhixin.com

















